Last modified: Sep 12, 2023
Scrapy xpath() - Find By Xpath
Today, we're going to learn how to find by Xpath using Scrapy. And explore how to effectively find and extract data using XPath expressions.
Visit this guide if you have not set up your Scrapy project before beginning.
What is Xpath
XPath (XML Path Language) is a language used for navigating XML and HTML documents.
You can use XPath to select elements and attributes within an XML or HTML document by specifying their paths.
How to get the Xpath of any element
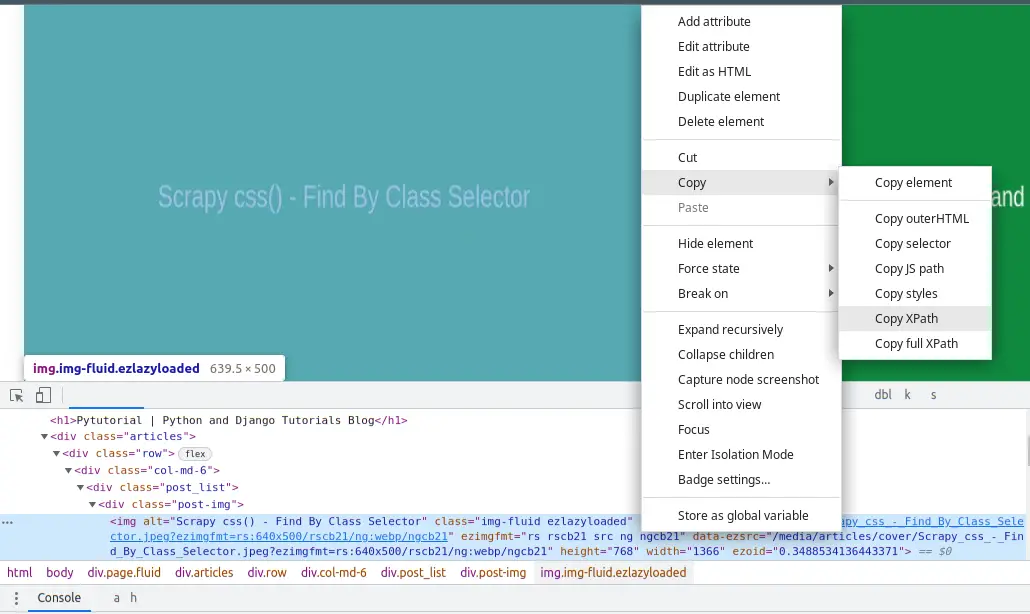
By using your browser, you can simply get the Xpath of any element. Here are the steps:
- Open the web page in Google Chrome.
- Open Chrome Developer Tools by pressing
Ctrl + Shift + I(orCmd + Option + Ion macOS) or right-clicking and selecting "Inspect" or pressingF12. - In Chrome Developer Tools, go to the "Elements" tab.
- Locate the element you want to find the XPath for by hovering over it or selecting it in the "Elements" tab.
- Right-click on the element.
- From the context menu, hover over "Copy" and then select "Copy XPath."
And, here's an example from Chrome:
How to Find By Xpath
To find by Xpath, we will use the xpath() method, which is used to locate and select elements from a web page's HTML or XML source code using XPath expressions.
Here is the syntax of the xpath() method:
response.xpath('xpath')To select all the <a> elements on a page, you can use the following XPath expression:
response.xpath('//a')To select all <a> elements with the class attribute set to "button," you can use:
response.xpath('//a[@class="button"]')To select all <p> elements that are children of a <div> element with class "article," you can use an XPath expression like this:
response.xpath('//div[@class="article"]/p')To select all <h2> elements with the exact text "Latest News," you can use:
response.xpath('//h2[text()="Latest News"]')These are just a few examples of selecting elements using the xpath() method. Now, let's make a Scrapy spider that gets all of the article titles and links from the home page of pytutorial.com.
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://pytutorial.com']
def parse(self, response):
articles = response.css('.post-title a')
for article in articles:
# Extract text from each selected <a> element (title)
title = article.css('::text').get()
# Extract the href attribute (link) from the <a> element
link = article.css('::attr(href)').get()
# Print or yield the extracted data as needed
yield {'title': title, 'link': link}To run the spider, here is the command:
scrapy crawl myspider -O data.jsonOutput of data.json:
[
{"title": "Scrapy - Find by ID Attribute", "link": "/scrapy-find-by-id"},
{"title": "Scrapy css() - Find By Class Selector", "link": "/scrapy-css-find-by-class-selector"},
{"title": "How to Install and Setup Scrapy", "link": "/how-to-install-and-setup-scrapy"},
{"title": "How to Append Multiple Items to List in Python", "link": "/python-append-multiple-list"},
{"title": "How to Use BeautifulSoup clear() Method", "link": "/how-to-use-beautifulsoup-clear-method"},
{"title": "Python: Add Variable to String & Print Using 4 Methods", "link": "/python-variable-in-string"},
{"title": "How to Use Beautifulsoup select_one() Method", "link": "/how-to-use-beautifulsoup-select_one-method"},
{"title": "How To Solve ModuleNotFoundError: No module named in Python", "link": "/how-to-solve-modulenotfounderror-no-module-named-in-python"},
{"title": "Beautifulsoup Get All Links", "link": "/beautifulsoup-get-all-links"},
{"title": "Beautifulsoup image alt Attribute", "link": "/beautifulsoup-image-alt-attribute"}
]Conclusion
By the end of this article, you will be able to find elements by the XPath selector using Scrapy. If you want to learn how to find elements by CSS selector, please visit the following articles:
Scrapy css() - Find By Class Selector
Additionally, if you'd like to explore finding elements by their ID attribute, you can check out: